Amikor a mesterséges intelligencia szaknyelvet tanul: nyelvi modellek a szövegosztályozásban
A Neumann János Informatikai Kar munkatársai által végzett tudományos munka, kutatási eredmények szélesebb körben való ismertetése céljából a honlapunkon kiemelkedő, válogatott közlemények tartalmát bemutató hírek.
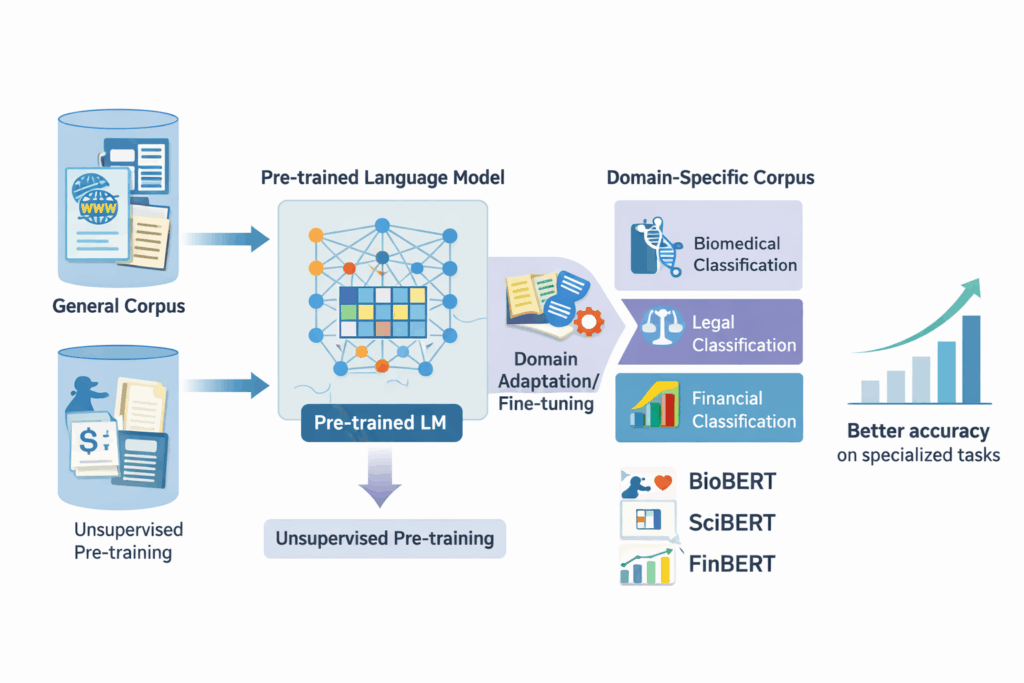
Az utóbbi években robbanásszerűen nőtt az interneten és a tudományos publikációkban megjelenő szöveges információ mennyisége. Ennek feldolgozásában kulcsszerepet játszik a természetesnyelv-feldolgozás (NLP), különösen a szövegosztályozás, amelynek célja például egy dokumentum témájának, hangulatának vagy kategóriájának automatikus meghatározása. Bár a modern nagy nyelvi modellek rendkívül sikeresek általános nyelvi feladatokban, teljesítményük gyakran romlik olyan speciális területeken, ahol sajátos szókincs, szaknyelv vagy erősen kiegyensúlyozatlan adathalmazok jelennek meg. A Kar kutatóinak nemrég megjelent tanulmánya ezt a problémát vizsgálja: azt elemezték, hogyan használhatók a előre betanított nyelvi modellek (pre-trained language models, PLM-ek) kifejezetten szakterületi szövegek osztályozására.
A szerzők egy szisztematikus irodalmi áttekintést készítettek, amelyben 41 tudományos cikket elemeztek a 2018 és 2024 közötti időszakból. Az elemzés a PRISMA módszertanra épült, amely egy elterjedt keretrendszer a szisztematikus szakirodalmi áttekintések elkészítésére. A vizsgált tanulmányok különböző alkalmazási területeket fedtek le, például a biomedicinát, a pénzügyet, a jogi szövegek feldolgozását vagy a közösségi médiából származó adatok elemzését. Az áttekintés feltérképezte, hogy milyen modelleket használnak (például BERT vagy GPT-alapú rendszereket), milyen módon alkalmazzák őket speciális területeken, és milyen adatkészleteken értékelik a teljesítményüket.
A tanulmány egyik fontos megállapítása, hogy az előre betanított nyelvi modellek jelentősen felülmúlják a korábbi, hagyományos gépi tanulási módszereket a szakterületi szövegklasszifikációs feladatokban. Az is kiderült, hogy az általános célra betanított modellek teljesítménye gyakran tovább javítható, ha azokat kifejezetten az adott szakterület adataival finomhangolják. Különösen hatékonynak bizonyultak az olyan megközelítések, mint a domain-specifikus előtanítás, az adatkiterjesztési technikák, valamint a különféle finomhangolási stratégiák. Az eredmények arra is rámutatnak, hogy bizonyos esetekben a kisebb, célzottan egy adott területre fejlesztett modellek versenyképesek vagy akár jobbak lehetnek, mint a nagyméretű, általános modellek.
A cikk arra is rávilágít, hogy a terület még számos nyitott kérdést tartalmaz. Gyakori probléma például a minőségi tanítóadatok hiánya, a szakterületi terminológia kezelése vagy az osztályok közötti egyensúlytalanság az adatkészletekben. A szerzők szerint a jövőbeli kutatások egyik fontos iránya a jobb adatelőállítási módszerek, a hatékonyabb domain-adaptáció, valamint az olyan modellek fejlesztése lehet, amelyek képesek rugalmasan alkalmazkodni különböző szakterületek nyelvezetéhez.
Az eredeti közlemény
Advances in Pre-trained Language Models for Domain- Specific Text Classification: A Systematic Review
The exponential increase in scientific literature and online information necessitates efficient methods for extracting knowledge from textual data. Natural language processing (NLP) plays a crucial role in addressing this challenge, particularly in text classification tasks. While large language models (LLMs) have achieved remarkable success in NLP, their accuracy can suffer in domain-specific contexts due to specialized vocabulary, unique grammatical structures, and imbalanced data distributions. In this systematic literature review (SLR), we investigate the utilization of pre-trained language models (PLMs) for domain-specific text classification. We systematically review 41 articles published between 2018 and January 2024, adhering to the PRISMA statement (preferred reporting items for systematic reviews and meta-analyses). This review methodology involved rigorous inclusion criteria and a multi-step selection process employing AI-powered tools. We delve into the evolution of text classification techniques and differentiate between traditional and modern approaches. We emphasize transformer-based models and explore the challenges and considerations associated with using LLMs for domain-specific text classification. Furthermore, we categorize existing research based on various PLMs and propose a taxonomy of techniques used in the field. To validate our findings, we conducted a comparative experiment involving BERT, SciBERT, and BioBERT in biomedical sentence classification. Finally, we present a comparative study on the performance of LLMs in text classification tasks across different domains. In addition, we examine recent advancements in PLMs for domain-specific text classification and offer insights into future directions and limitations in this rapidly evolving domain.
K. Rostam, Zhyar Rzgar, and Gábor Kertész. "Advances in pre-trained language models for domain-specific text classification: A systematic review." ACM Transactions on Intelligent Systems and Technology 16.6 (2025): 1-41.
DOI: 10.1145/3763002
BibTeX
@article{k2025advances,
title={Advances in pre-trained language models for domain-specific text classification: A systematic review},
author={K. Rostam, Zhyar Rzgar and Kert{\'e}sz, G{\'a}bor},
journal={ACM Transactions on Intelligent Systems and Technology},
volume={16},
number={6},
pages={1--41},
year={2025},
publisher={ACM New York, NY}
}